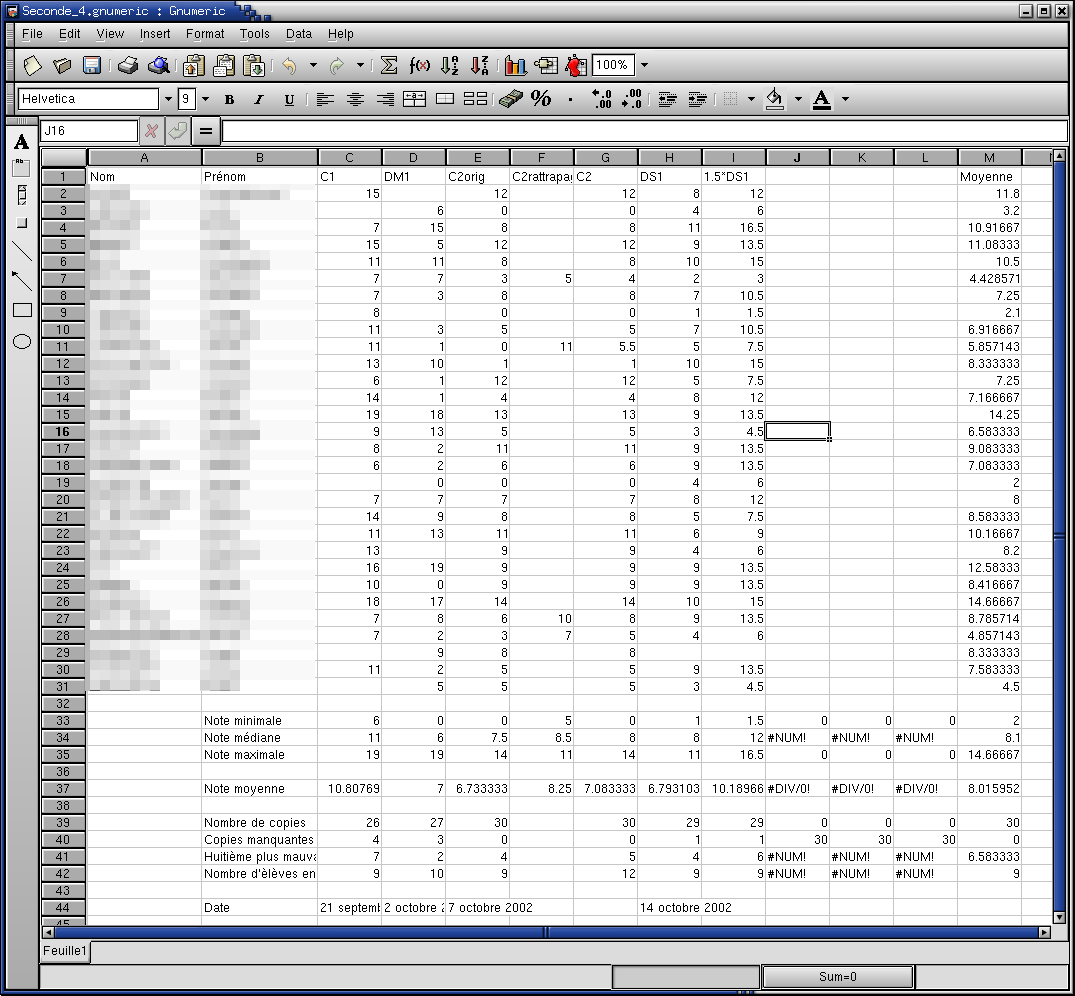
Cette année, je me retrouve prof en lycée (Grrrr...). Pour taper les notes de mes élèves, les visualiser et calculer les moyennes, j'ai tenté d'utiliser un tableur (gnumeric), mais devant le manque de flexibilité de ce genre d'outil, je me suis finalement tourné vers un logiciel de statistiques : R.
Un tableur, c'est un logiciel qui permet de remplir des tableaux avec des nombres, des chaines de caractères, ou des formules. Par exemple, on peut mettre, le nom des élèves dans une première colonne, leur prénom dans une deuxième, leurs notes dans les colonnes suivantes, et demander à l'ordinateur de faire la moyenne dans la dernière colonne. Autre exemple, pour les commerçants, on peut mettre le code d'un article dans une colonne, le prix unitaire dans une autre, le nombre d'articles commandés dans une autre et le prix total dans une dernière colonne ; il y a alors une ligne par article, plus une dernière ligne avec le total.
De manière plus générale, un tableur, c'est une grosse machine à calculer, grosse en ce sens qu'elle permet de faire de grosses additions.
Comme tableur, j'ai choisi gnumeric.
http://www.gnome.org/projects/gnumeric/
Mais il en existe d'autres, qui présentent probablement les mêmes fonctionnalités.
http://www.openoffice.org/ http://www.koffice.org/kspread/ http://siag.nu/index.shtml
On peut taper des formules simples (un seul appel de fonction) à l'aide du cliquodrome : c'est pratique si on ne connait pas très bien le nom ou les arguments des fonctions.

On peut aussi taper les formules directement, comme si c'était du texte : pour que le tableur comprenne qu'il s'agit bien d'une formule, il suffit de la faire commencer par le signe =. Par exemple, on pourra taper << =median(B1:B20) >>.
Plutôt que de taper les numéros de cases à la main, on peut les sélectionner à la souris (en plein milieu de la saisie de la formule).
Attention ! En français, il faut séparer les arguments de fonctions par un point-virgule (en anglais, c'est une virgule) et utiliser une virgule dans les nombres décimaux (et pas un point comme en anglais)... Je trouve plus simple de lancer gnumeric en anglais :
unset `set | grep -E -a '^(LC|LANG)' | sed 's/=.*//'` gnumeric Seconde.gnumeric &
On peut alors faire des traitements statistiques un peu plus poussés que la moyenne. Voici quelques fonctions que je trouve utiles.
max Valeur maximale
min Valeur minimale
median Valeur médiane
percentiles
large k-ième plus grande valeur
small k-ième plus petite valeur
rank rang d'une valeur
count nombre de valeurs numériques
counta nombre de cases
mean Moyenne arithmétique
trimmean Moyenne après avoir enlevé les valeurs les plus
élevées et les plus basses.
stdevp Déviation standard (d'une population)Exemple 1. Les élèves les plus mauvais auront droit à une séance d'"aide individuelle". Voici la huitième note à partir du bas.
=small( B1:B30 ; 8 )
Voici le nombre d'élèves concernés (il peut y en avoir plusieurs qui ont cette note-là).
=count( B1:B30 ) - rank( B31 ; B1:B30 ; 0 ) + 1
J'aimerais bien avoir la liste des élèves concernés, mais avec gnumeric seul, je ne sais pas faire, du moins, pas de manière automatique.
Exemple 2. Pour les relevés de notes trimestriels, je calcule les moyennes « gentillement » : j'enlève systématiquement la note la plus basse.
=(sum(A1:A12)-small(A1:A12,1))/(count(A1:A12)-1)
Je n'arrive pas à demander à gnumeric le nom des huit élèves les plus mauvais.
Je n'arrive pas à faire la moyenne d'un ensemble de cases non contiguës.
Je n'arrive pas à représenter graphiquement les données.
Je n'arrive pas à obtenir des représentation graphiques non élémentaires (par exemple, l'analyse en composantes principales, avec le graphe des valeurs propres) des données.
R est un logiciel de statistiques (un équivalent gratuit, et même libre, de S ou S-plus), avec lequel on peut programmer, et donc avec lequel je ne serai pas limité. L'autre gros logiciel de statistiques commercial est SAS, dont un équivalent libre semblerait être DAP (Data Analysis and Presentation), que je ne connais pas.
http://www.gnu.org/software/dap/dap.html
On doit aussi pouvoir faire un peu de statistique avec Matlab et ses clones, SciLab ou Octave.
http://www-rocq.inria.fr/scilab/ http://www.octave.org/
Pour lancer R, c'est très simple : on tape << R >>. Et on se retrouve avec une belle interface textuelle...
% R R : Copyright 2002, The R Development Core Team Version 1.5.1 (2002-06-17) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under certain conditions. Type `license()' or `licence()' for distribution details. R is a collaborative project with many contributors. Type `contributors()' for more information. Type `demo()' for some demos, `help()' for on-line help, or `help.start()' for a HTML browser interface to help. Type `q()' to quit R. > 1+1 [1] 2 > demo() > demo(graphics)
En fait, on peut aussi demander une interface graphique.
R --gui=GNOME

Mais revenons à Gnumeric. Dans un premier temps, j'ai envisagé de continuer à utiliser gnumeric pour taper les notes et R pour faire les calculs et les dessins.
Pour cela, après avoir tapé les notes, je dois sauvegarder le fichier au format CSV,



puis enlever les lignes ou colonnes dont je n'a pas besoin (celles qui contiennent des calculs que gnumeric est capable de faire),
perl -p -i -e 'if(!$b){m/(,*)$/;$a=$1;$b=1}s/$a$//;exit if m/^,*$/' tmp.csvpuis charger le fichier sous R
?read.table
notes = read.table("tmp.csv", header=TRUE, sep=",", dec=".")
notes$note
[1] 8 15 14 16 8 5 11 16 12 6 11 7 8 4 12 14 14 13 6 11 11 1 3 14 14
[26] 13 1 14 10 15 19 5 2 17 10puis tracer l'histogramme des notes.
hist(notes$note)

On peut aussi comparer les notes de deux devoirs
pairs(cbind(Seconde13$C1, Seconde13$DS1))

Les commandes hist et pair sont les deux principales à connaitre. Voici néanmoins d'autres exemples de graphiques.
hist(notes$note, probability=TRUE, breaks=2*c(0:10)) points(density(notes$note,bw=1), type='l')

boxplot(notes$note)

x <- notes[,3] y <- notes[,4] plot(y~x) abline(0,1) abline(lm(y ~ x))
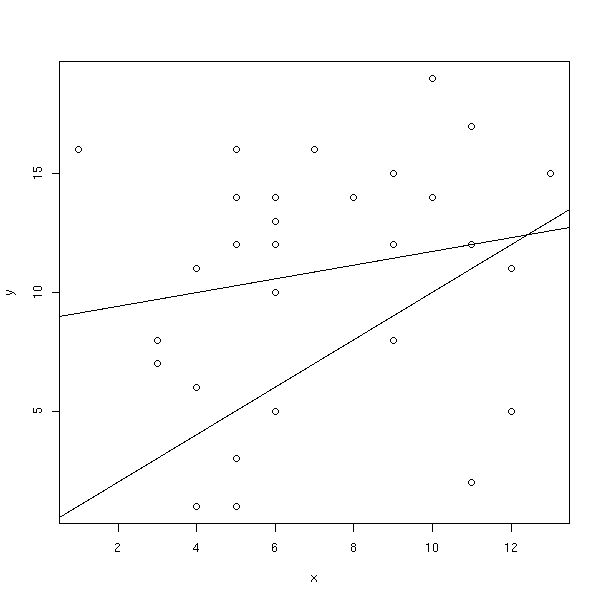
Les dessins png ont été réalisés ainsi :
?Devices ?postscript ?png png(filename="hist1.png", width=600, height=600, pointsize=12, bg="white") hist(note$note) dev.off()
Mais je trouve très pénible de devoir à chaque fois exporter le fichier au format csv, puis de le nettoyer : je décide finalement de ne plus utiliser que R.
Avant de pouvoir programmer un peu, il est nécessaire de bien comprendre les types de données que manipule R.
Il y a trois valeurs booléennes : TRUE, FALSE et NA (Not Available).
Un vecteur (de nombres ou de chaines de caractères : tous les éléments doivent avoir le même type) (ici, « c » signifie « concaténer »).
x = c(1,2,5,3,6,3,4,0)
n = c('foo', 'bar', 'baz')Un facteur, c'est à peu près comme un vecteur de chaines de caractères, mais R suppose que chaque chaine peut apparaitre plusieures fois et stocke donc les données en deux morceaux : d'une part la liste des chaines de caractères qui apparaissent, d'autre part le vecteur, qui ne contient plus des chaines, mais simplement le numéro d'ordre de la chaine dans la liste précédente. C'est donc ce qu'il est naturel de manipuler quand on est face à une variable qualitative. On peut convertir un facteur en un vecteur de chaines de caractères à l'aide de la commande as.vector.
Un Data Frame, c'est une liste de vecteurs, ayant tous la même taille. On rappelle que les éléments d'un même vecteur (i.e., d'une même colonne) doivent tous avoir le même type.
?data.frame
Attention : si une colonne d'un Data Frame contient des chaines de caractères, elle est automatiquement convertie en facteur. Or, les facteurs ont tendance à être convertis en vecteur numériques, ce qui n'est pas du tout ce que l'on veut. Il faut penser à les convertir explicitement, avec as.vector().
Les listes sont comme des vecteurs, sauf qu'elles peuvent contenir n'importe quel type de données (nombres, chaines de caractères, vecteurs, autres listes, etc.). Je les utilise comme tables de hachage :
h = list() ... h[["foo bar"]] = ... ...
La commande is.null permet de savoir si la table de hachage contient la valeur que l'on cherche :
if( is.null( h[[as.character(i)]] ) ){
...
}
Créer un vecteur (« c » comme « concaténer ») :
c(1,3,5,2,3,4)
Mettre le résultat d'un calcul dans une variable :
x <- c(1,3,5,2,3,4)
ou
x = c(1,3,5,2,3,4)
Longueur d'un vecteur :
length(x)
Vecteur vide :
x = vector(mode="numeric")
Ajouter un élément à un vecteur :
x = append(x, 156)
ou
x = c(x, 156)
Empiler plusieurs vecteurs (lignes) pour faire une matrice :
m <- rbind(x, y, z)
Concaténer plusieurs vecteurs (colonnes) pour faire une matrice :
m <- cbind(x, y, z)
Créer un vecteur contenant les nombres de 0 à 10 :
x <- 0:10
Tracer une fonction (une fenêtre apparait) :
x <- (0:20)/10 y <- x^2 +x + 1 plot( y~x, type="l" )
Un sous-vecteur, défini par un vecteur d'indices :
x[c(1,4,8,3)]
Un vecteur de booléens :
x>1
Un sous-vecteur défini par un vecteur de booléens :
x[ x>1 ]
Vérifier qu'un élément d'un vecteur (ou autre) est bien défini :
is.na(x[1])
Le sous-vecteur des éléments effectivement définis de x :
x[ ! is.na(x) ]
Les opération booléennes sont !, & et | :
x[ !is.na(x) & x>1 ]
Une ligne d'un tableau de dimension 2 :
m[1,]
Une colonne d'un tableau de dimension 2 :
m[,1]
Un Data Frame, c'est presque comme un tableau : les colonnes doivent toutes avoir le même nombre d'éléments ; les colonnes sont des vecteurs (donc les éléments d'une même colonne ont tous le même type, contrairement aux listes) ; les colonnes contenant des chaines de caractères sont automatiquement converties en facteurs. On peut créer un Data Frame
> data.frame(foo=c(1,2,3), bar=c('a', 'b', 'c'))
foo bar
1 1 a
2 2 b
3 3 cou le lire depuis un fichier CSV
?read.table
ou depuis l'entrée standard
a = scan()
Les colonnes d'un Data Frame portent un nom, que l'on peut utiliser pour y accéder :
Seconde13$DS1
ou
Seconde12[["DS1"]]
Appliquer une fonction à chaque ligne d'un tableau (le « 1 » signifie « première dimension », i.e., ligne) :
apply(cbind(Seconde4$DM1, Seconde4$DS1), 1, mean)
On peut remettre le résultat dans un tableau :
data.frame( nom = Seconde4$Nom,
moyenne = apply(cbind(Seconde4$DM1, Seconde4$DS1), 1, mean)
)
Pour la saisie du nom des élèves et des notes, on peut utiliser le tableur intégré à R. C'est beaucoup plus rudimentaire que gnumeric, mais ça suffira.
notes <- edit(notes)
On peut avoir besoin de changer le nom d'une colonne.
# Liste des noms de colonnes attributes(notes) attr(notes,"names") attr(notes,"names")[6] = "DS2";
On peut aussi avoir besoin de réordonner les lignes du tableau. (Ne pas oublier as.vector pour convertir la colonne du data.frame en un vecteur de chaines de caractères : sinon, on a un vecteur de nombres...)
o = order(as.vector(PremiereSTT$Nom))
for (d in 1:length(PremiereSTT)) {
PremiereSTT[,d] = PremiereSTT[,d][o]
}Les lignes ont un nom : je leur donne le nom des élèves.
row.names(Seconde13) <- as.vector(Seconde13[,1])
Voici la première version du code que j'ai utilisé pour gérer les notes de mes élèves. C'est assez mal écrit, voyez plutôt la version suivante, un peu plus loin.
moyenne = function (x, ...) {
if( any(is.na(x)) | length(x)==1 ){
return( mean(x, na.rm=T, ...) );
} else {
return( ( sum(x, na.rm=F) - min(x, na.rm=F) )/(length(x)-1) );
}
}
vectorCorrectLength <- function (v, l) {
# It should be a vector, and not a factor...
v <- as.vector(v)
for ( i in 1:l )
v <- append(v, "")
v[1:l]
}
appendToDataFrame <- function (df, name, v) {
if( length(df)>0 ){
l = max( length(df[,1]), length(v) )
d = data.frame( vectorCorrectLength(df[,1], l) )
if( length(df)>1 ){
for ( i in 2:length(df) ) {
d = data.frame( d, vectorCorrectLength(df[,i], l) )
}
}
d = data.frame( d, vectorCorrectLength(v, l) )
attr(d, "names") = c( attr(df, "names"), name )
} else {
d = data.frame(v)
attr(d, "names") = c(name);
}
d
}
panel.hist <- function(x, ...) {
usr <- par("usr"); on.exit(par(usr))
par(usr = c(usr[1:2], 0, 1.5) )
h <- hist(x, plot = FALSE)
breaks <- h$breaks; nB <- length(breaks)
y <- h$counts; y <- y/max(y)
rect(breaks[-nB], 0, breaks[-1], y, ...)
}
notes <- function ( classe, pire=FALSE, devoirs=NA, ... ) {
df = data.frame()
nb_eleves <- length(classe[,1])
if( is.na(devoirs) ){
devoirs = attr(classe, "names")
devoirs = devoirs[3:length(list)]
}
v1 = vector(mode="numeric")
v2 = vector(mode="numeric")
for (i in 1:length(classe[,1]) ){
n = vector(mode="numeric");
m = classe[i,];
for (j in devoirs) {
n = append(n, m[[j]])
}
v1 = append(v1, round(mean(n, na.rm=T), digits=2))
v2 = append(v2, round(moyenne(n), digits=2))
}
names <- attr(classe, "names")
classe = data.frame(classe, v1, v2, classement(v2))
attr(classe, "names") <- c(names, "Moyennes", "Moyennes", "Classement")
for (d in 1:length(classe[1,])) {
# On regarde s'il faut garder la colonne
garder = FALSE
for (n in c(devoirs, "Moyennes", "Classement", "Nom", "Prénom")){
if( n == attr(classe,"names")[d] )
garder = TRUE
}
if(!garder) next
print(paste("Processing row", d, attr(classe,"names")[d]))
# On récupère les valeurs précédentes
valeurs = vector(mode="character")
valeurs = append(valeurs, as.character(classe[,d]))
# On calcule les moyennes, etc.
if( attr(classe,"names")[d] == "Nom" ){
valeurs = append(valeurs, c("Min", "Median", "Max", "Missing", "Mean", "StdDev"))
if(pire){
valeurs = append(valeurs, c("Eighth worst mark", "number", "names"))
}
} else if( attr(classe,"names")[d] != "Nom"
& attr(classe,"names")[d] != "Prénom"
& attr(classe,"names")[d] != "Classement"
){
print("***"); print(d); print( attr(classe,"names")[d] )
valeurs = append(valeurs, round( min(classe[,d], na.rm=T), digits=2))
valeurs = append(valeurs, round( median(classe[,d], na.rm=T), digits=2))
valeurs = append(valeurs, round( max(classe[,d], na.rm=T), digits=2))
valeurs = append(valeurs, round( length( (classe[,d])[ is.na(classe[,d]) ] ), digits=2))
valeurs = append(valeurs, round( mean(classe[,d], na.rm=T), digits=2))
valeurs = append(valeurs, round( sd(classe[,d], na.rm=T), digits=2))
# Les huit notes les plus mauvaises
if (pire) {
notes = as.vector( classe[,d] )
noms = as.vector( classe[,1] )
eight = sort(notes)[8];
valeurs = append(valeurs, eight)
eleves = noms[ (!is.na(notes)) & (notes <= eight) ]
valeurs = append(valeurs, paste( length(eleves), "élèves"))
valeurs = append(valeurs, eleves)
}
}
df = appendToDataFrame(df, attr(classe, "names")[d], valeurs)
}
affiche(df)
# Graphiques
gr=vector(mode="numeric")
for (d in 1:length(classe[1,])) {
garder = FALSE
for (n in c(devoirs, "Moyennes")){
if( n == attr(classe,"names")[d] )
garder = TRUE
}
if(garder)
gr=append(gr, d)
}
## The resulting postscript file can be used by dvips -Ppfb -j0 ??????
# postscript(file="RESULT.eps", onefile=TRUE, family="ComputerModern")
postscript(file="RESULT.eps", onefile=TRUE, horizontal=TRUE)
pairs(classe[,gr], diag.panel=panel.hist,
upper.panel=panel.smooth,
lower.panel=panel.smooth);
dev.off();
cat("\\includegraphics[angle=-90]{RESULT.eps}\n", file="RESULT.tex", append=TRUE)
cat("\\end{document}\n", file="RESULT.tex", append=TRUE)
}
affiche <- function (df) {
print("*** Affiche")
print(df)
cat("\\documentclass{article}\n", file="RESULT.tex", append=FALSE)
cat("\\usepackage[latin1]{inputenc}\n", file="RESULT.tex", append=TRUE)
cat("\\usepackage[T1]{fontenc}\n", file="RESULT.tex", append=TRUE)
cat("\\usepackage[a4paper,dvips,landscape=true,left=1cm,right=1cm,top=1cm,bottom=1cm,nohead,nofoot]{geometry}\n", file="RESULT.tex", append=TRUE)
cat("\\usepackage{graphicx}\n", file="RESULT.tex", append=TRUE)
cat("\\def\\globble\#1\{\}\n", file="RESULT.tex", append=TRUE)
cat("\\parindent=0pt\n", file="RESULT.tex", append=TRUE)
cat("\\pagestyle{empty}\n", file="RESULT.tex", append=TRUE)
cat("\\usepackage{dcolumn}\n", file="RESULT.tex", append=TRUE)
cat("\\newcolumntype{.}{D{.}{.}{2,2}}\n", file="RESULT.tex", append=TRUE)
cat("\\begin{document}\n", file="RESULT.tex", append=TRUE)
cat("\\begin{tabular}{|l|l|", file="RESULT.tex", append=TRUE)
for ( i in 3:length(df) ){
#cat(".|", file="RESULT.tex", append=TRUE)
cat("c|", file="RESULT.tex", append=TRUE)
}
cat("}\n", file="RESULT.tex", append=TRUE)
cat("\\hline\n", file="RESULT.tex", append=TRUE)
cat("\\globble ", file="RESULT.tex", append=TRUE)
for ( i in attr(df,"names") ){
cat("&", file="RESULT.tex", append=TRUE)
cat(i, file="RESULT.tex", append=TRUE)
}
cat("\\\\\n", file="RESULT.tex", append=TRUE)
cat("\\hline\n", file="RESULT.tex", append=TRUE)
for (i in 1:length( attr(df,"row.names") )) {
if( df[i,1] == "Min" ){
cat("\\hline\n", file="RESULT.tex", append=TRUE)
}
cat("\\globble ", file="RESULT.tex", append=TRUE)
for (j in df[i,]) {
cat("&", file="RESULT.tex", append=TRUE)
cat(as.vector(j), file="RESULT.tex", append=TRUE)
}
cat("\\\\\n", file="RESULT.tex", append=TRUE)
}
cat("\\hline\n", file="RESULT.tex", append=TRUE)
cat("\\end{tabular}\n\n", file="RESULT.tex", append=TRUE)
}
classement <- function (x) {
a = sort(x)
l = length(a)
h = list() # hash table
for (i in a) {
h[[as.character(i)]] = l
l = l-1
}
result = vector(mode="numeric")
for (i in x) {
if( is.null( h[[as.character(i)]] ) ){
result = append(result, NA)
} else {
result = append(result, h[[as.character(i)]])
}
}
result
}Je l'utilise ainsi :
notes(Seconde4, devoirs=c("DM1", "C1", "C2", "DS1", "DS1", "DM2"))
notes(Seconde4, pire=TRUE, devoirs=c("DM2"))
notes(Seconde13, devoirs=c("C1", "DM1", "DS1", "DS1", "DM2"))
notes(PremiereSTT, devoirs=c("DM1", "DS1", "DS1", "DM2"))
notes(Seconde4, devoirs=c("C3", "DM3", "DM4", "DS2", "DS2", "DM5"))
notes(Seconde13, devoirs=c("C2", "DM3", "DM4", "DS2", "DS2", "DM5"))
notes(PremiereSTT, devoirs=c("DM3", "DS2", "DS2"))
notes(TerminaleSTT, devoirs=c("DS2", "DS2", "DM3"))On peut formuler quelques critiques sur le code précédent.
Le code pour convertir en LaTeX est particulièrement horrible. Il aurait fallu l'isoler dans une fonction pour créer des tableaux -- d'ailleurs, une telle fonction existe déjà : xtable.
Avant d'être converti en LaTeX, le tableau est un tableau de chaines de caractères. Je ne pouvais pas utiliser de data.frame, car dans certaines colonnes, je voulais pouvoir mettre à la fois des données numériques et des chaines de caractères, mais j'aurais tout à fait pu utiliser une liste (i.e., une chaine de hachage).
La fonction pour calculer la moyenne devrait être passée en argument : pour certaines classes, je calcule une moyenne gentille, en enlevant la plus mauvaise note, mais pas pour d'autres (car ils ont moins de mathématiques, donc moins de notes).
La structure de données contenant les notes pourrait être plus complexe, et contenir la liste des devoirs, leur date, leur trimestre, leurs coefficients et la fonction pour calculer la moyenne.
On pourrait imaginer quelque chose de plus général, qui consisterait à implémenter un tableur en R, i.e., un tableau contenant à la fois des données et des formules, auquel seraient "attachées" diverses fonctions (méthodes) pour mettre à jour les données ou pour faire des graphiques.
Au niveau des graphiques : il en manque quelques uns, comme l'analyse en composantes principales des notes (mais elle ne dit pas grand-chose) (j'ai changé le nom des élèves),


une boite à moustaches pour chaque élève,

l'évolution des notes (soit les notes normalisées, soit le classement) de chaque élève,

un dendogramme,

l'aggrégation autour des centres mobiles,

etc.
Voici la seconde version de ce code.
library(cluster)
my.debug.msg <- function (...) {
cat("DEBUG: ")
cat(paste(...))
cat("\n")
}
my.debug.print <- function (x) {
cat("DEBUG: ")
print(x)
}
my.debug.msg("Defining function: moyenne")
moyenne.gentille = function (x, coef) {
if( any(is.na(x)) | length(x)==1 ){
return( weighted.mean(x,coef, na.rm=T) )
} else {
i <- order(x)[1]
if( coef[i] <1 ){
coef[i] <- 0
} else {
coef[i] <- coef[i] - 1
}
return( weighted.mean(x,coef) )
}
}
moyenne.default <- function (x,coef) {
weighted.mean(x,coef, na.rm=T)
}
my.debug.msg("Defining function: panel.hist")
panel.hist <- function(x, ...) {
usr <- par("usr"); on.exit(par(usr))
par(usr = c(usr[1:2], 0, 1.5) )
h <- hist(x, plot = FALSE)
breaks <- h$breaks; nB <- length(breaks)
y <- h$counts; y <- y/max(y)
rect(breaks[-nB], 0, breaks[-1], y, ...)
}
my.debug.msg("Defining function: classement")
classement <- function (x) {
a = sort(x)
l = length(a)
h = list() # hash table
for (i in a) {
h[[as.character(i)]] = l
l = l-1
}
result = vector(mode="numeric")
for (i in x) {
if( is.null( h[[as.character(i)]] ) ){
result = append(result, NA)
} else {
result = append(result, h[[as.character(i)]])
}
}
result
}
my.debug.msg("Defining function count.missing")
count.missing <- function (x) {
sum(is.na(x))
}
my.debug.msg("Defining function: nouvelleClasse")
nouvelleClasse <- function (classe, eleves) {
C <- list()
C$classe <- classe
C$eleves <- eleves
C$notes <- NULL
C$devoirs <- list()
C$trimestres <- list()
C
}
my.debug.msg("Defining function: nouveauDevoir")
nouveauDevoir <- function (C, name, trimestre, coef=1, date=NULL, data=NULL) {
C$devoirs[[name]] = list(name=name, date=date, trimestre=trimestre, coef=coef)
eleves <- C$eleves
l <- data.frame( rep(NA,length(eleves)), row.names=eleves)
names(l) <- name
if( length(data)==0 ) {
l <- edit(l)
} else {
l[[name]] <- data
}
if( length(C$notes) == 0 ){
C$notes <- l
} else {
C$notes <- data.frame(C$notes, l)
}
C
}
my.debug.msg("Defining function: editNotes")
editNotes <- function (C, devoir) {
l <- data.frame( C$notes[[devoir]], row.names=row.names(C$notes) )
names(l) <- devoir
l <- edit(l)
C$notes[[devoir]] <- l[1]
C
}
my.debug.msg("Defining tex.table")
tex.sanitize <- function (x) {
if( is.null(x) ) {
x <- ""
}
if( is.character(x) ) {
x <- gsub("\\\\", "\\\\", x)
x <- gsub("\\&", "\\\&", x)
x <- gsub("\\$", "\\\$", x)
x <- gsub("\\{", "\\\{", x)
x <- gsub("\\}", "\\\}", x)
x <- gsub("\\%", "\\\%", x)
x <- gsub("\\^", "\\\^{}", x)
x <- gsub("\\~", "\\\~", x)
x <- gsub("\\#", "\\\#", x)
x <- gsub("\\_", "\\\_", x)
}
if( is.numeric(x) ) {
x <- floor(100*x+.5)/100
x <- as.character(x)
x <- gsub("-", "$-$", x)
}
if( is.na(x) ) {
x <- ""
}
x
}
tex.table <- function (m) {
mypaste <- function (...) {
paste(..., sep='', collapse='')
}
m <- as.matrix(m)
res <- ""
res <- mypaste(res, "\\begin{tabular}{|l|")
res <- mypaste(res, mypaste(rep("c|", dim(m)[2])))
res <- mypaste(res, "}\n")
res <- mypaste(res, " \\hline\n ")
for (j in 1:dim(m)[2]){
res <- mypaste(res, "&")
res <- mypaste(res, tex.sanitize(colnames(m)[j]))
}
res <- mypaste(res, "\\\\\n ")
for (i in 1:(dim(m)[1])) {
res <- mypaste(res, "\\hline\n ")
res <- mypaste(res, tex.sanitize(rownames(m)[i]))
for (j in 1:(dim(m)[2])) {
res <- mypaste(res, "&", tex.sanitize(m[i,j]))
}
res <- mypaste(res, "\\\\\n ")
}
res <- mypaste(res, "\\hline\n")
res <- mypaste(res, "\\end{tabular}\n")
cat(res, file="RESULT.tex", append=TRUE)
}
tex.table3 <- function (a,b,c) {
d <- cbind(a,b)
e <- cbind(c, matrix(nrow=dim(c)[1], ncol=dim(b)[2]) )
# Pourquoi est-ce que ça ne marche pas avec des data.frames ?
f <- rbind(as.matrix(d),as.matrix(e))
print( dim(f) )
print( colnames(f) )
print( dim(d) )
print( names(d) )
colnames(f) <- names(d)
tex.table(f)
}
my.debug.msg("Defining hash table: output.x11")
output.x11.start <- function () {}
output.x11.stop <- function () {}
output.x11.open <- function (n) {
par(ask=T)
}
output.x11.close <- function () { }
output.x11.table3 <- function (a,b,c) { print( cbind(a,b) ); print(c) }
output.x11 <- list(
open=output.x11.open,
close=output.x11.close,
start=output.x11.start,
stop=output.x11.stop,
table3=output.x11.table3,
)
my.debug.msg("Defining hash table: output.tex")
output.tex.start <- function () {
cat("\\documentclass{article}\n", file="RESULT.tex", append=FALSE)
cat("\\usepackage[latin1]{inputenc}\n", file="RESULT.tex", append=TRUE)
cat("\\usepackage[T1]{fontenc}\n", file="RESULT.tex", append=TRUE)
cat("\\usepackage[a4paper,dvips,landscape=true,left=1cm,right=1cm,top=1cm,bottom=1cm,nohead,nofoot]{geometry}\n",
file="RESULT.tex", append=TRUE)
cat("\\usepackage{graphicx}\n", file="RESULT.tex", append=TRUE)
cat("\\def\\globble\#1\{\}\n", file="RESULT.tex", append=TRUE)
cat("\\parindent=0pt\n", file="RESULT.tex", append=TRUE)
cat("\\pagestyle{empty}\n", file="RESULT.tex", append=TRUE)
cat("\\usepackage{dcolumn}\n", file="RESULT.tex", append=TRUE)
cat("\\newcolumntype{.}{D{.}{.}{2,2}}\n", file="RESULT.tex", append=TRUE)
cat("\\begin{document}\n", file="RESULT.tex", append=TRUE)
}
output.tex.stop <- function () {
cat("\\end{document}\n", file="RESULT.tex", append=TRUE)
}
output.tex.open <- function (n) {
postscript(file=paste("classe_", n, ".eps", sep=''),
horizontal=FALSE,
paper="special",
width=10, height=6,
pointsize=10)
cat("\\begin{center}\n", file="RESULT.tex", append=TRUE)
cat(" \\leavevmode\n", file="RESULT.tex", append=TRUE)
#cat(paste(" \\includegraphics{classe_", n, ".eps}\n", sep=''), file="RESULT.tex", append=TRUE)
cat(paste(" \\fbox{\\includegraphics{classe_", n, ".eps}}\n", sep=''), file="RESULT.tex", append=TRUE)
cat("\\end{center}\n", file="RESULT.tex", append=TRUE)
}
output.tex.close <- function () {
dev.off()
}
output.tex <- list(
open=output.tex.open,
close=output.tex.close,
start=output.tex.start,
stop=output.tex.stop,
table3=tex.table3,
)
my.debug.msg("Defining function: bulletin")
bulletin <- function (C, trimestre, output=output.x11) {
my.debug.msg("(bulletin) Getting test names")
devoirs <- NULL
coefs <- NULL
for (i in C$devoirs) {
if( i$trimestre == trimestre ) {
devoirs <- append(devoirs, i$name)
coefs <- append(coefs, i$coef)
}
}
my.debug.print(devoirs)
my.debug.msg("(bulletin) Gathering the marks")
# Les notes pertinentes
B <- NULL
for (i in devoirs) {
B <- cbind(B, C$notes[[i]])
}
B <- data.frame(B)
row.names(B) <- row.names(C$notes)
my.debug.print(B)
names(B) <- devoirs
# Nom des variables :
# B : notes des élèves
# B1 : moyennes
# B2 : classement
# B0 : notes avec les moyennes des élèves (concaténation de B et B1)
# B3 : moyenne, etc. de chaque devoir
# Le tableau que l'on veut imprimer a donc la forme suivante.
# ------ ------
# | B0 | B2 |
# ------ ------
# | B3 |
# ------
my.debug.msg("(bulletin) Finding the 'mean' function")
moyenne <- NULL
try( moyenne <- C$trimestres[[as.character(trimestre)]]$moyenne )
if( is.null(moyenne) ) {
try( moyenne <- C$trimestres[[trimestre]]$moyenne )
}
if( is.null(moyenne) ) {
moyenne <- moyenne.default
}
my.debug.print(moyenne)
my.debug.msg("(bulletin) Building the tables")
# On rajoute la moyenne de chaque élève
B1 <- data.frame(moyenne=apply(B,1,moyenne, coefs), row.names=row.names(B))
B2 <- data.frame(classement=classement(B1$moyenne))
B0 <- data.frame(B,B1)
# On ajoute la moyenne de chaque devoir
B3 <- data.frame(min=apply(B0,2,min,na.rm=T))
B3 <- data.frame(B3, median=apply(B0,2,median,na.rm=T))
B3 <- data.frame(B3, max=apply(B0,2,max,na.rm=T))
B3 <- data.frame(B3, mead=apply(B0,2,mean,na.rm=T))
B3 <- data.frame(B3, sd=apply(B0,2,sd,na.rm=T))
B3 <- data.frame(B3, missing=apply(B0,2,count.missing))
B3 <- t(B3)
output$start()
my.debug.msg("(bulletin) Printing the tables")
op <- options(digits=2)
output$table3( B0, B2, B3 )
options(op)
op <- par()
my.debug.msg("(bulletin) Boxplots")
# C'est très maladroit. J'aurais bien voulu faire de n
# une variable statique ou globale, mais nous sommes
# face à un langage sans effet de bord...
n <- 1
n <- n+1; output$open(n)
boxplot(B0, main="Notes des devoirs")
output$close()
n <- n+1; output$open(n)
opl<-par(mar=c(5,15,4,2))
#opl<-par(mfrow=c(1,2))
#boxplot(data.frame(t(B)), horizontal=T, las=1, main="Notes des élèves")
boxplot(data.frame(t(scale(B))), horizontal=T, las=1,
main="Notes normalisées des élèves")
par(opl)
output$close()
my.debug.msg("(bulletin) scattermatrix")
n <- n+1; output$open(n)
pairs(B0, diag.panel=panel.hist,
upper.panel=panel.smooth,
lower.panel=panel.smooth,
main="Corrélation entre les différents devoirs");
output$close()
my.debug.msg("(bulletin) PCA")
n <- n+1; output$open(n)
Bna <- B
for (i in 1:dim(B)[2]) {
Bna[is.na(B[,i]),i] <- median(B[,i], na.rm=T)
}
biplot(princomp(Bna),
main="Décomposition en composantes principales")
output$close()
my.debug.msg("(bulletin) PCA screeplot")
n <- n+1; output$open(n)
plot(princomp(Bna),
main="Valeurs propres de la décomposition en composantes principales")
output$close()
my.debug.msg("(bulletin) Dendogram")
n <- n+1; output$open(n)
try( plot(hclust(dist(B)), hang=-1) )
try( plot(hclust(dist(scale(B))), hang=-1) )
output$close()
my.debug.msg("(bulletin) Clusters")
n <- n+1; output$open(n)
opl<-par(mfrow=c(2,2))
for (i in 2:5)
try( clusplot( B, pam(B, i)$clustering ) )
par(opl)
output$close()
par(op)
output$stop()
}Je convertis les anciennes données ainsi :
S4 <- nouvelleClasse("Seconde 4", paste(Seconde4$Nom, Seconde4$Prénom))
for (d in c("C1", "DM1", "C2", "DS1", "DM2")) {
S4 <- nouveauDevoir(S4, d, trimestre=1, coef=1, data=Seconde4[[d]])
}
for (d in c("C3", "DM3", "DM4", "DS2", "DM5", "DM6")) {
S4 <- nouveauDevoir(S4, d, trimestre=2, coef=1, data=Seconde4[[d]])
}
S4$devoirs$DS1$coef <- 2
S4$devoirs$DS2$coef <- 2
S4$trimestres[[1]] <- list(moyenne = moyenne.gentille)
S4$trimestres[[2]] <- list(moyenne = moyenne.gentille)
Dans le document suivant, je vais reprendre cette présentation de R, de manière beaucoup plus approfondie, non plus pour gérer mes notes, mais pour faire des statistiques. Comme je ne connais pour l'instant rien à cette discipline, ça prend plus de temps que prévu : soyez patients, et rendez-vous dans quelques mois. (J'écris ces lignes en janvier 2003.)
../48_R/all.html
Vincent Zoonekynd
<zoonek@math.jussieu.fr>
latest modification on Sun Oct 26 19:43:56 CET 2003