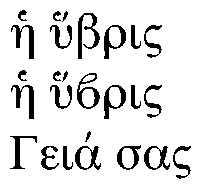
Voici un fichier simple.
\documentclass[a4paper,12pt]{article}
\usepackage[english]{babel}
\usepackage{omega}
\begin{document}
This is our first file with \OMEGA.
\end{document}On le compile à l'aide de la commande lambda et non plus latex (lambda est l'équivalent de latex, omega celui de tex, gamma celui de ConTeXt).
lambda 1.tex
On peut visualiser le résultat (un fichier dvi illisible par xdvi) à l'aide de la commande oxdvi (si elle marche).
oxdvi 1.dvi
On peut aussi convertir le résultat en PostScript (du PostScript tout à fait normal) à l'aide de la commande odvips (la commande dvips ne marchera pas).
odvips -o 1.ps 1.dvi gv 1.ps
Le paquetage omega.sty permet d'utiliser la fonte standard d'Oméga. Pour les langues utilisant le codage latin1, comme le français, on peut les taper directement. Pour les autres langues alphabétiques, on dispose d'environements greek, arab, smallarab, latberber, tifinagh, berber, urdu, smallurdu, pashto, pashtop, sindhi.
Comme je ne connais aucune de ces langues, je ne sais pas trop quel codage on est sensé utiliser à l'intérieur de ces environements et je ne peux pas vraiment faire de tests. Prenons l'exemple du grec. Regardons dans le fichier omega.sty comment l'environement greek est défini.
\newenvironment{greek}{%
\pushocplist\GreekOCP
\fontfamily{omlgc}\selectfont%
\language=3%
\lefthyphenmin=2%
\righthyphenmin=2%
}{%
}La première ligne demande de charger la liste d'OCP (c'est ce qui permet de passer du codage d'entrée, celui qu'on a utilisé pour taper le texte, par exemple UTF8 ou latin1, au codage de sortie, utilisé par la fonte, par exemple OT1 ou T1). Cette liste d'OTP est définie ainsi.
\ocp\GrTexUni=grpo2uni \ocp\GrUniToFont=uni2greek \ocplist\GreekOCP= \addbeforeocplist 1 \GrTexUni \addbeforeocplist 1 \GrUniToFont \nullocplist
La liste d'OCP est constituée de deux éléments : un premier OCP \GrTexUni, décrit dans un fichier grpo2uni.otp, qui convertit du codage d'entrée vers le codage interne utilisé par Oméga, et un deuxième OCP, \GrUniToFont, décrit dans un fichier uni2greek.otp, qui passe de ce codage interne au codage de la fonte. Pour savoir quel est le codage d'entrée, regardons le contenu du fichier grpo2uni.otp.
Si on a de la chance, le nom du codage est évident d'après le nom du fichier ou est mentionné en commentaires au début de celui-ci : nous n'avons pas de chance.
input: 1; output: 2; expressions: `<'`''`a'`|' => #(@"1F85) ; `<'`''`h'`|' => #(@"1F95) ; `<'`''`w'`|' => #(@"1FA5) ; `<'`='`a'`|' => #(@"1F87) ; ... `A' => #(@"0391) ; `B' => #(@"0392) ; `D' => #(@"0394) ; `E' => #(@"0395) ; `F' => #(@"03A6) ; `G' => #(@"0393) ; ...
Le codage est alors relativement évident : pour avoir la lettre alpha, on tape a, de même pour la plupart des autres lettres. On devine que pour avoir divers accents, il suffit de les saisir avant la lettre (par exemple <'u). Mais pour d'autres caractères, ce n'est peut-être pas si évident. Cherchons par exemple comment taper le sigma final. En Unicode, c'est le caractère U+02C2.
http://www.unicode.org/charts/
On cherche donc dans l'OTP quel caractère est envoyé sur ce code : il s'agit du caractère c. Certains caractères ne sont pas là, par exemple le bêta non-initial, U+03D0 : on peut les taper en saisissant directement leur code Unicode, ^^^^02D0. Pour être sûr que le caractère est là, on peut consulter la table des caractères de la fonte standard d'Oméga
http://www.lps.ens.fr/~ebrunet/omega/omlgc.ps
On peut donc maintenant taper du texte grec.
\documentclass[a4paper,12pt]{article}
\usepackage[english]{babel}
\usepackage{omega}
\begin{document}
\pagestyle{empty}
\begin{greek}
<h <'ubric
<h <'u^^^^03d0ric
Gei'a sac
\end{greek}
\end{document}
On procèderait de même pour les autres langues.
Note : pour le grec, on remarque qu'on charge un fichier supplémentaire
\input{grlccode.tex}Ce fichier indique à Oméga quels caractères sont des lettres (c'est utile pour la césure).
Tous ces environements ne tiennent pas compte de la césure, i.e., ignore les règles utilisées pour couper les mots en fin de phrase. Pire encore, lambda ne dait pas faire la césure des langues pourtant reconnues par LaTeX : pas exemple, si on essaye d'utiliser du français (avec babel), on obtient le message suivant.
Babel <v3.7h> and hyphenation patterns for english, greek, loaded. ... Package babel Warning: No hyphenation patterns were loaded for (babel) the language `French' (babel) I will use the patterns loaded for \language=0
instead.
Si des fichiers de motifs de césure existent pour la langue en question, on peut les utiliser directement (je suis persuadé que ça ne devrait pas marcher, qu'il faudroit convertir les motifs de césure en Unicode, mais je suis forcé de constater que ça marche très bien). Pour cela, il faut modifier le fichier language.dat utilisé par Lambda
kpsewhich --progname=lambda language.dat
afin qu'il charge le fichier de motifs de césure désirés Pour savoir exactement ce qu'il faut mettre dans ce fichier, il suffit de regarder le contenu de celui utilisé par LaTeX. Par exemple, mon fichier language.dat contenait
% File : language.dat % Purpose : specify which hypenation patterns to load % while running iniTeX english ushyphen.tex %french frhyphen.tex greek elhyph16.tex
Il contient désormais
% File : language.dat % Purpose : specify which hypenation patterns to load % while running iniTeX english ushyphen.tex french frhyphen.tex greek elhyph16.tex
On vérifier que ça marche (les seuls problèmes sont suceptibles de venir des caractères accentués, car les autres sont des caractères ASCII, et sont donc les mêmes dans tous les codages).
\documentclass[a4paper,12pt]{article}
\usepackage[english,frenchb]{babel}
\usepackage{omega}
\begin{document}
\pagestyle{empty}%
\selectlanguage{frenchb}%
\showhyphens{bécébégé}
\end{document}Dans le fichier *.log, on lit
[][] \OT1/omlgc/m/n/12 b^^e9-c^^e9-b^^e9g^^e9
On compare avec ce que l'on avait avec LaTeX (il faut rajouter \usepackage[latin1]{inputenc} et \usepackage[T1]{fontenc} pour que ça marche).
[] \T1/cmr/m/n/12 bé-cé-bégé
Tout cela est bien beau, mais on aimerait avoir un peu plus de choix sur le codage qu'on utilise. Par exemple, pour le grec, le codage usuel est ISO-8859-7, mais on pourrait aussi utiliser UTF8 si on désire mélanger plusieures langues. Pour cela, il suffit en fait de redéfinir l'environement greek (défini dans omega.sty) pour qu'il utilise un autre OTP d'entrée.
Par exemple, pour le codage ISO-8859-7, on regarde s'il n'y aurait pas déjà un OTP d'entrée.
locate .otp | grep 8859
Il y en a un, qui s'appelle in88597.otp. On l'utilise donc ainsi.
\documentclass[a4paper,12pt]{article}
\usepackage[english]{babel}
\usepackage{omega}
\ocp\GrIsoUni=in88597
\ocplist\GreekOCP=
\addbeforeocplist 1 \GrIsoUni
\addbeforeocplist 1 \GrUniToFont
\nullocplist
\begin{document}
\pagestyle{empty}
\begin{greek}
ÃåéÜ óáò
\end{greek}
\end{document}On procèderait de même pour UTF8 : l'OTP d'entrée s'appelle alors inutf8.
Pour écrire localement de droite à gauche :
\beginR ... \endR
C'est comme cela que sont définis les environements correspondant aux langues s'écrivant de droite à gauche.
\newenvironment{arab}{%
\pushocplist\ArabicOCP
\fontfamily{omarb}\selectfont
\beginR
}{%
\endR
}
A FAIRE
L'utilisation d'Oméga avec d'autres fontes, avec d'autres langues (en particulier les langues asiatiques) est beaucoup plus compliquée et fera l'objet d'un autre document.
Vincent Zoonekynd
<zoonek@math.jussieu.fr>
latest modification on lun mai 6 14:30:03 CEST 2002